
Task Dependent Importance of Small Singular Values During Fine-Tuning
View the full project on GitHub
Short Description
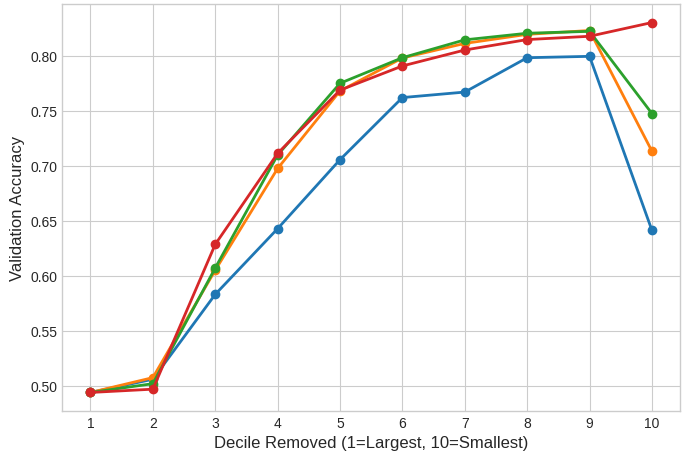
In this project, I removed singular values from a fine-tuned transformer to study their role in model alignment. I discovered that the smallest singular values are critical during early fine-tuning, but their importance fades with longer training. These results suggest opportunities for smarter, layer specific pruning strategies via singular value decomposition.
Abstract
Singular value decomposition (SVD) is vital for model compression, enabling matrix approximation with fewer parameters. In this work, we systematically remove singular values (SVs) from fine-tuned DistilBERT models across GLUE tasks of varying complexity. Our experiments show that small SVs are essential for complex reasoning during early fine-tuning, though their importance diminishes with prolonged training. We localize these performance-critical small SVs primarily to early feed-forward network layers in the transformer. These findings enable optimized compression schemes that preserve essential small SVs in critical regions while permitting aggressive pruning elsewhere.